Hadoop的运行环境介绍
hadoop主要有三种运行模式:单机模式、伪分布模式、完全分布模式。
其中在单机模式下所有3个XML文件均为空,当配置文件为空时,Hadoop会完全运行在本地,因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
在伪分布式模式下是指在“单节点集群”上运行Hadoop,其中所有的守护进程都运行在同一台机器上,即Jobtracker、Tasktracker、Namenode、Datanode、Secondarynamenode进程都运行在同一台主机上。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
完全分布式模式是将hadoop运行在了一个真正的集群上,该集群内含有一个主节点master,及至少两个的从节点slave;其中主节点上主要运行Namenode、Jobtracker、Secondarynamenode进程,从节点主要运行Datanode、Tasketracker进程。这种模式下可以真正实现hadoop的分布式处理,有主节点对从节点的任务分配调度以及HDFS在主机间的输入输出。
Hadoop集群搭建准备工作
需要提前下载好的文件:
- ubuntu-16.04.5-desktop-amd64.iso
- jdk-8u144-linux-x64.tar
- hadoop-2.7.2.tar
虚拟机准备
在Parallels Desktop中新建一台虚拟机,快照并克隆三次,得到了三台虚拟机
注意:快照的是为了节省自己的硬盘空间
使三台虚拟机连通
先使用命令
ifconfig查看三台虚拟机的ip地址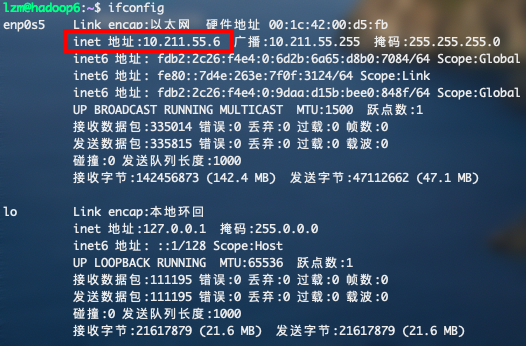
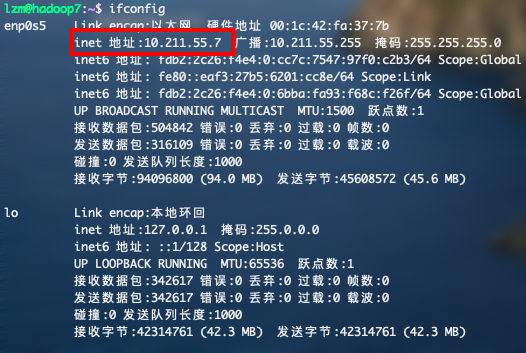
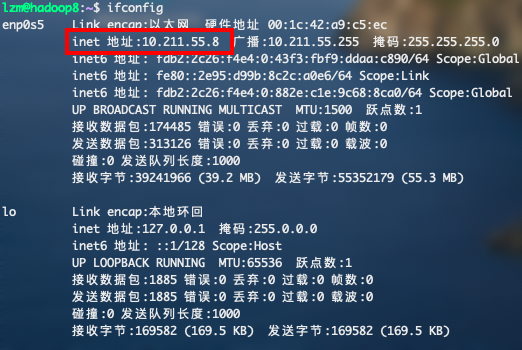
然后使用命令
sudo vim /etc/hostname修改主机名

这里就拿一个演示,剩下的两台也改
注意:我是以ip地址末尾来命名的,你也可以使用master,slave1,slave2命名,只要自己可以分辨出虚拟机是哪台就行
然后我们添加该局域网内的集群中其他虚拟主机ip
使用命令
sudo vim /etc/hosts将和主机名一样的ip地址注释掉并添加三台主机的ip和主机名,修改具体情况如下: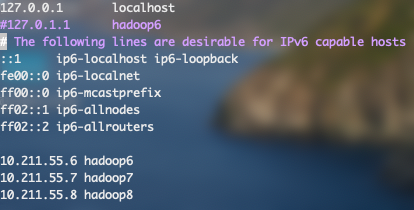
三台虚拟机都需要这样配置
然后使用命令
ping -c 3 hadoop7测试互相可以ping通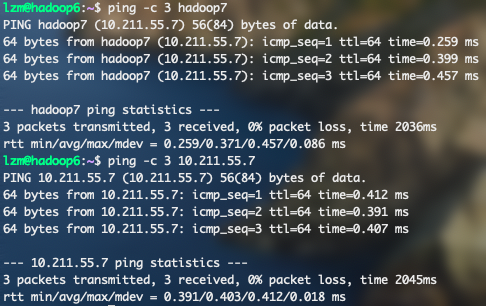
配置免密登陆
先使用命令
ssh localhost,如果提示输入密码那么就代表你有ssh,如果出现connect to host localhost port 22:Connection refused那么请参考:Ubuntu下 ssh : connect to host localhost port 22:Connection refused安装好ssh后可以使用命令
ssh-keygen -t rsa -P '',提示输入密钥保存的路径,直接按enter键使用默认值即可然后使用命令
ssh-copy-id hadoop6将空钥发到本机,同样需要发到hadoop7,hadoop8然后另两台服务器也需要这样配置
配置好后可以使用
ssh hadoop6登录虚拟机,使用exit可以推出登录安装JDK和Hadoop
使用命令
mkdir /opt/module /opt/software在/opt下创建software和module文件夹并使用命令
chown lzm:lzm /opt/module /opt/software将所有权赋给当前用户可以使用
ls -l来进行查看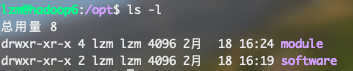
将JDK和Hadoop的安装包复制到software文件夹,然后使用命令
tar -zxf hadoop-2.7.2.tar.gz -C /opt/module,tar -zxf jdk-8u144-linux-x64.tar.gz -C /opt/module将其安装到module目录下同样两台都进行配置
配置环境变量
使用命令
sudo vim /etc/profile在文件后面添加1
2
3
4
5
6
7#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin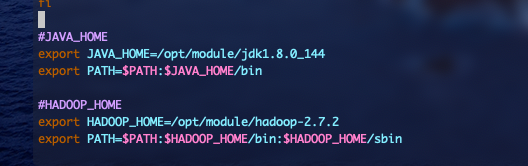
保存后使用命令
source /etc/profile重新启动一下配置,然后使用java -version和hadoop version来测试一下环境变量是否配置完成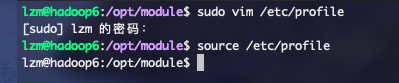


另外两个虚拟机也是同样的
配置Hadoop
- 注意:所有配置文件都在
$HADOOP_HOME/etc/hadoop
首先配置
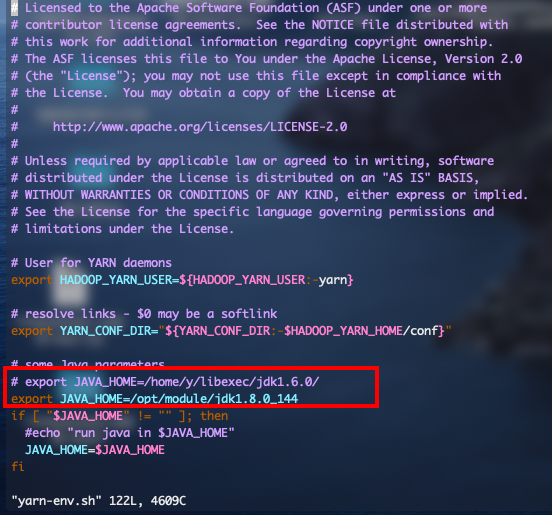
hadoop-env.sh,yarn-env.sh,mapred-env.sh文件,在每个文件第二行添加export JAVA_HOME=/opt/module/jdk1.8.0_144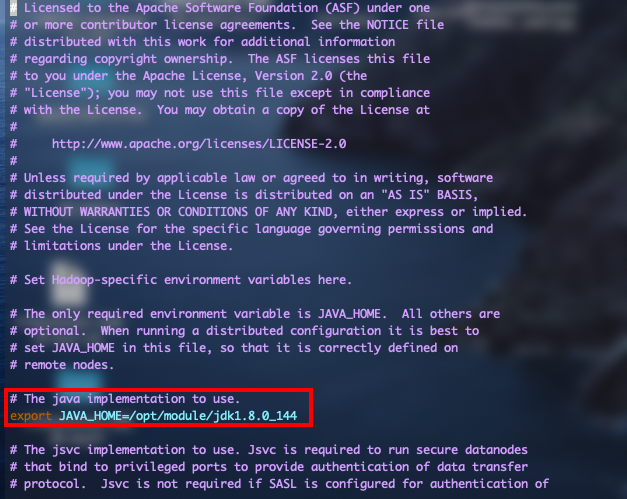
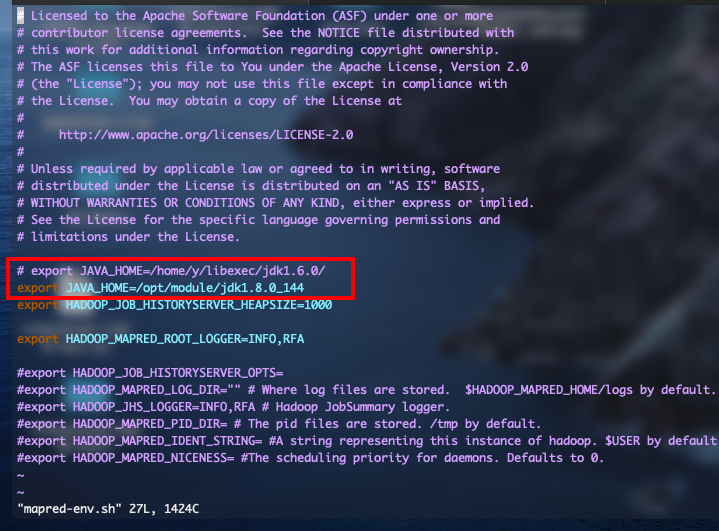
- 注意:所有配置文件都在
2. 配置`core-site.xml`,在文档中添加
1
2
3
4
5
6
7
8
9
10
11
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop6:9000</value><!-- 这里改成自己的主机名 -->
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>

3. 配置`hdfs-site.xml`,在文档中添加
1
2
3
4
5
6
7
8
9
10
<!-- 数据的副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop8:50090</value><!-- 这里改成自己的主机名 -->
</property>

4. 配置`yarn-site.xml`,在文档中添加
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
<!-- Site specific YARN configuration properties -->
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop7</value><!-- 这里改成自己的主机名 -->
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>

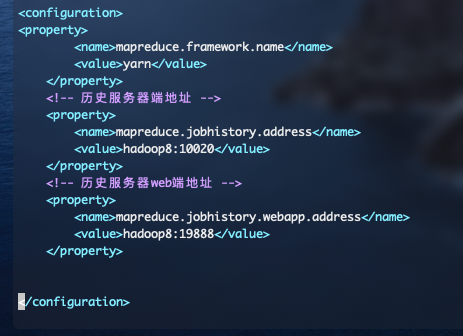
5. 配置`mapred-site.xml`,这个文档先需要使用命令`cp mapred-site.xml.template mapred-site.xml`复制一份然后在文档中添加
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop8:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop8:19888</value>
</property>
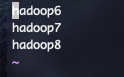
6. 配置`slaves`,在文档中添加
1
2
3
hadoop6
hadoop7
hadoop8
这样一台虚拟机就配置好了,我们可以讲以上步骤重复一遍或者使用命令`rsync -av/opt/module/hadoop-2.7.2/etc lzm@hadoop7:/opt/module/hadoop-2.7.2/etc`,hadoop8也是一样(如果使用命令操作的话,更换`lzm@hadoop7`为自己的)启动hadoop集群
完成了上述的步骤,伪分布式hadoop集群就搭建好了,下面我们启动集群
第一步:
在hadoop6上输入命令
hdfs namenode -format,这一步是初始化Namenode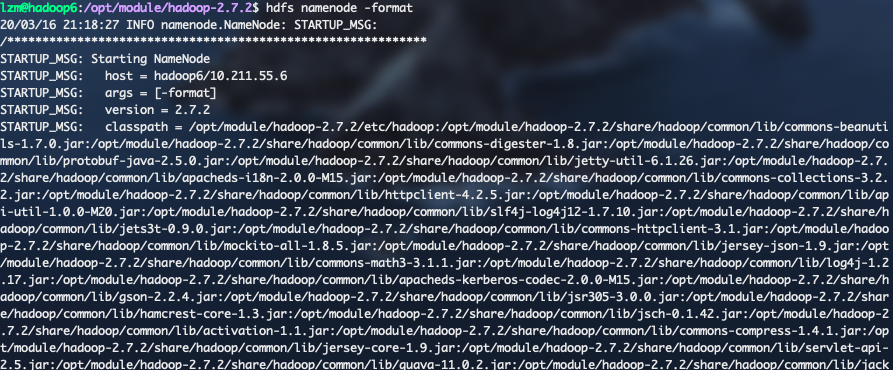
第二步:
格式化完成后在hadoop6上输入命令
start-dfs.sh启动HDFS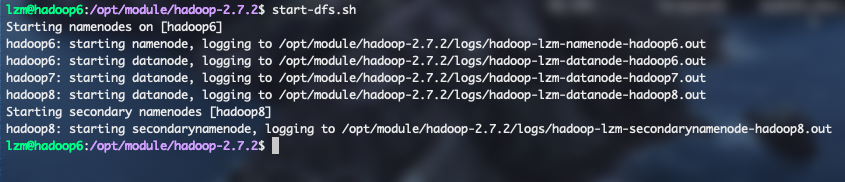
第三步:
然后在hadoop7(配置Resourcemanager的机器)上启动yarn,使用命令
start-yarn.sh
这是可以使用
jps来查看一下启动的服务是否正确,如果和下图一样就是安装完成了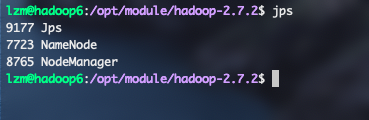
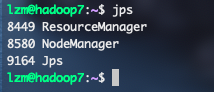
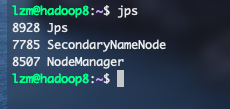
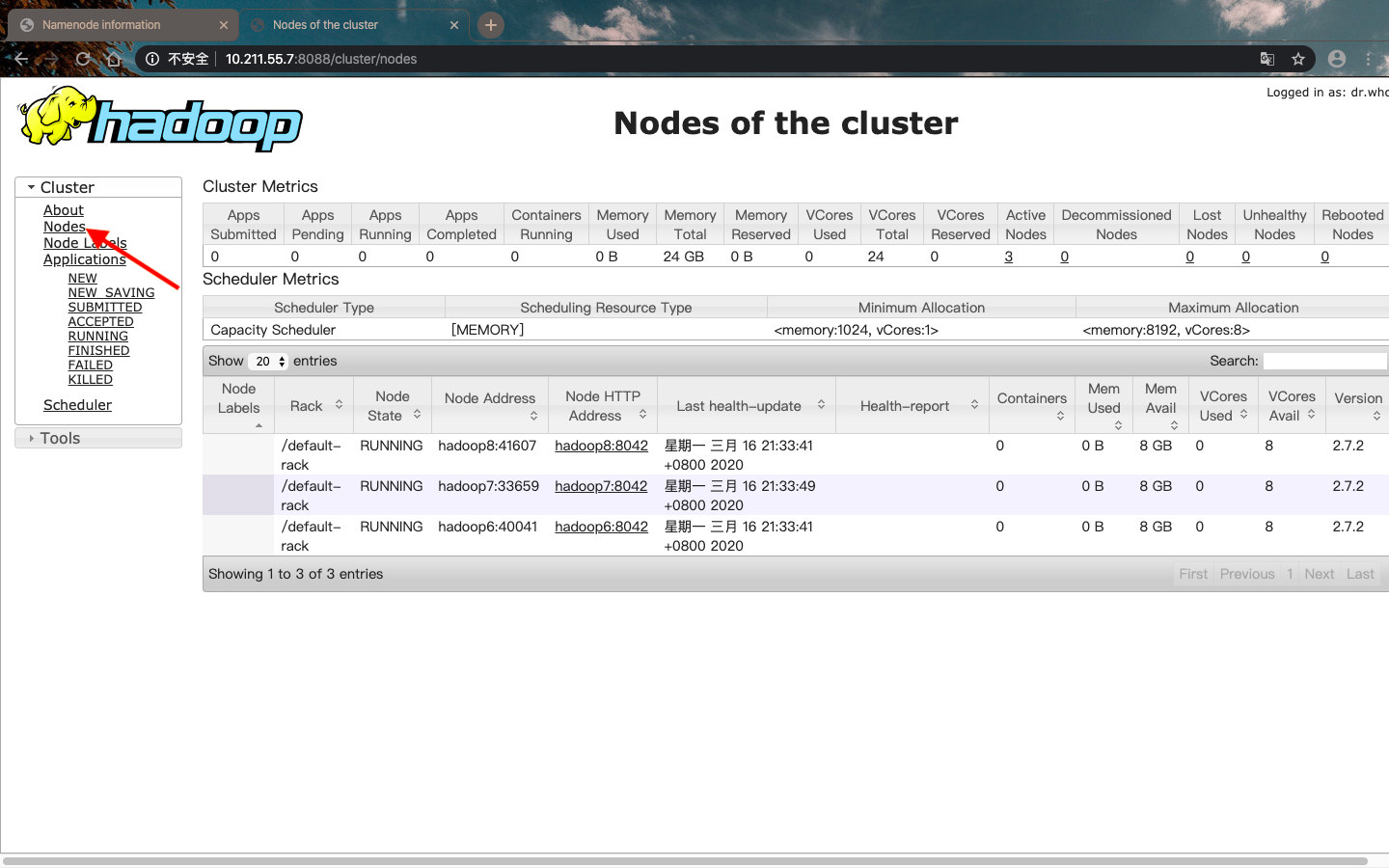
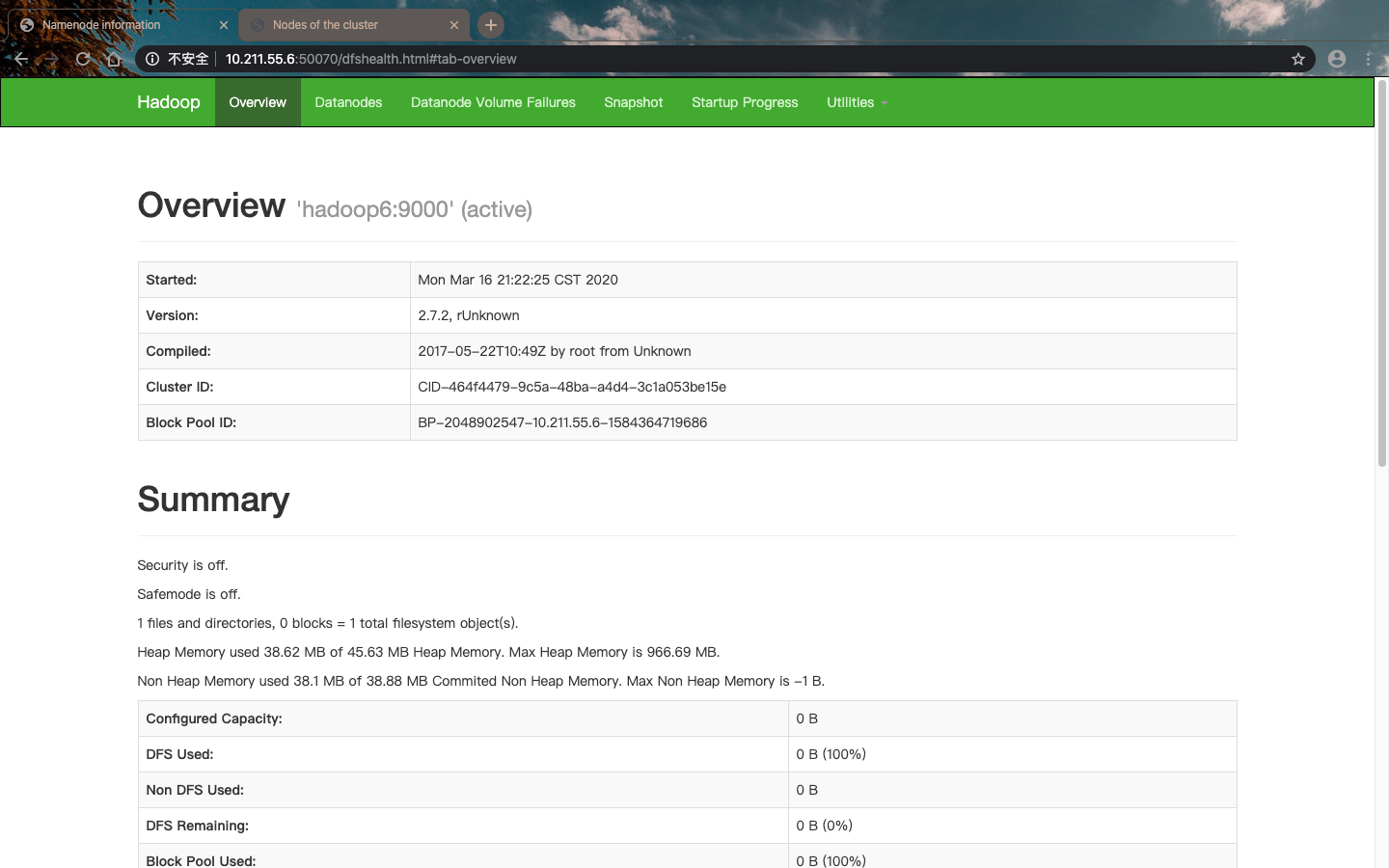
这样我就可以在浏览器中输入10.211.55.6:50070和10.211.55.7:8088来查看hadoop的页面